Ermittlung der Laufstreckenverteilung
aus den „Schadteilen“
Übersicht, Methoden, Software, Schulungen -> www.crgraph.de
Wie eingangs beschrieben, lässt sich die Laufstreckenverteilung auch aus den
Angaben der Schadteile ermitteln. Hierzu werden für jedes Schadteil folgende
Angaben benötigt:
- Fahrzeugzulassung
- Reparaturdatum
- Kilometerleistung
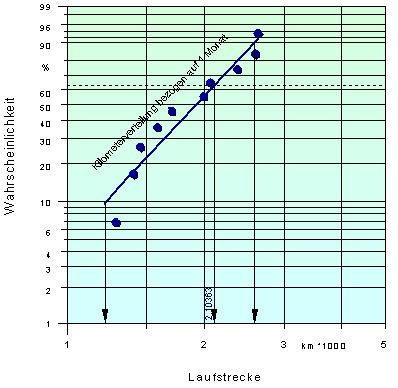
Aus der Differenz von Reparaturdatum - Fahrzeugzulassung erhält man die „Einsatzzeit“ des Bauteiles. Diese Daten trägt man in eine Tabelle zusammen mit der Kilometerleistung ein. Da sich eine Laufstreckenverteilung nur für gleiche Einsatzzeiten ermitteln lässt, normiert man diese Daten gleich auf einen Monat, d.h. man teilt die Laufstrecke durch die Einsatzzeit.
Der Schnittpunkt der aus diesen
Angaben erzeugten Ausgleichsgerade mit der 10%, 63.2% und 90% Häufigkeit
(Wahrscheinlichkeit) ergibt die gesuchten Kilometerwerte bei diesen Punkten.
Hierzu sind Lotlinien bei den entsprechenden Häufigkeiten zu ziehen (siehe
Beispiel rechts). Die ermittelten Werte können jetzt direkt in die eigentliche
Weibull-Auswertung übernommen werden. Als Vorlage für diese Berechnung dient
die Datei Weibull_Laufstreckenverteilung.vxg.
Vorlage zur Berechnung der
Prognoselinie
Zur Berechnung der Anwärter bzw. der Prognoselinie ist eine Dateivorlage notwendig. Diese lautet Weibull_Anwärter_Neu.vxg.
Speichern Sie nach dem Laden dieser
Datei diese für Ihre eigenen Daten in einem anderen Verzeichnis mit einem neuen
Namen ab.
Öffnen Sie die Tabelle mit der
entsprechenden Ikone zur Eingabe Ihrer Daten. Es erscheinen folgende Angaben
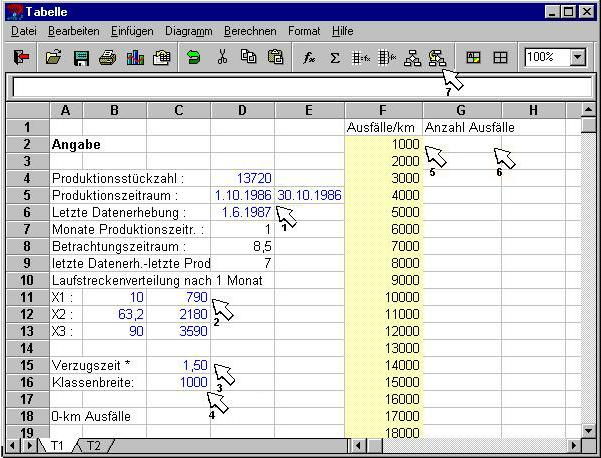
1 Hier erfolgt die Eingabe der Produktionsstückzahl, sowie der dazugehörige Produktionszeitraum. Es werden nur die Monatsangaben berücksichtigt. Die letzte Datenerhebung ist der Zeitpunkt an dem die letzten Informationen über die Feldausfälle bzw. Beanstandungen bekannt wurden.
2 Hier sind die Kilometerwerte in C11 bis C13 für die Laufstreckenverteilung einzutragen.
3 Hier wird die Verzugszeit eingegeben. Diese ist die Zeit in Monaten zwischen tatsächlicher Produktion und Zulassung, sowie die Zeit durch Verzögerungen in der Datenbereitstellung
4 Die Klassenbreite ist der Kilometerrange innerhalb dessen die konkreten Ausfälle zusammengefasst werden. Je nach Differenz des kleinsten und größten Kilometerwertes ist hier ein Wert von 1000 bis 10000km sinnvoll. Soll keine Klassierung durchgeführt werden, ist hier der Wert 1 einzutragen.
5 In der Spalte F werden die Kilometerwerte der Ausfälle bzw. Beanstandungen eingetragen. Aus vorhergehenden Eingaben vorhandene Werte sind zu löschen. Laden Sie nicht eine Excel-Datei um bereits vorhanden Daten einzulesen, da sonst die Tabelle überschrieben wird. Kopieren Sie statt dessen die Daten über die Zwischenablage in die Spalte F.
Nach dem Start des Programms (7) werden diese in Abhängigkeit der Klassenbreite zusammengefasst und Häufigkeiten in der Spalte G gebildet. Die Originaldaten werden dadurch überschrieben. Sollen diese weiterhin gespeichert bleiben, so ist vor der Berechnung die Spalte F z.B. in die Spalte H zu kopieren.
6 In Spalte G können optional Einzelhäufigkeiten angegeben werden, wenn bereits eine Vorklassierung durchgeführt wurde und für einen oder mehrere Kilometerwerte mehr als ein Ausfall vorhanden ist. Ist die Spalte G leer, so wird automatisch die Einzelhäufigkeit 1 eingetragen.
7 Mit der Ikone Programmstart wird die Berechnung gestartet, indem zunächst die Klassierung erfolgt und letztlich das Diagramm automatisch aufgebaut wird.
Zurück zur Hauptseite
Übersicht,
Methoden, Software, Schulungen -> www.crgraph.de